olrlobt
[추천 알고리즘] Spotify ANNOY (Approximate Nearest Neighbors Oh Yeah) 알고리즘이란? 본문
[추천 알고리즘] Spotify ANNOY (Approximate Nearest Neighbors Oh Yeah) 알고리즘이란?
olrlobt 2024. 4. 20. 00:10추천 알고리즘
이번에 진행한 프로젝트의 도메인은 '빅데이터 추천'이었다. 나는 추천 시스템에 관한 지식이 전혀 없는 상태였기에 여러 가지 학습한 내용을 정리하고, 내가 사용한 추천 알고리즘에 대해 작성하려 한다.
이 프로젝트의 요구사항은 사용자가 작성한 일기(글)를 기반으로 비슷한 내용의 다른 일기를 K개 추천하는 것이었다.
그렇다면, 어떻게 코드로 사용자가 작성한 일기와 비슷한 일기들을 찾을 수 있을까?
먼저, 숫자와 숫자의 유사도를 비교한다고 생각해 보자. 우리는 숫자와 숫자의 유사도를 비교할 때, 단순히 비교하는 숫자들의 거리차이가 가까울수록 유사도가 높다고 말한다. 이는 단어나 글에서도 똑같이 적용될 수 있는데, 단어를 컴퓨터가 이해할 수 있도록 숫자 배열로 표현한 임베딩 벡터값을 이용하면 된다.
단어와 단어 사이의 유사도를 찾는 것에 임베딩 벡터를 이용하는 방법은 자연어 처리(NLP) 분야에서 매우 널리 사용되는 기법이다. 그리고 마찬가지로, 글과 글 사이의 유사도를 찾는 것에도 똑같이 임베딩 벡터를 이용할 수 있다. 단어를 임베딩 벡터로 변환하기 위해서는 대표적으로 구글에서 개발한 Word2 Vec 모델이 있고, 글을 임베딩 벡터로 변환하기 위해서는 대표적으로 Doc2 Vec 모델이 있다. 하지만, Doc2 Vec 모델은 학습 과정에 따라 반의어의 임베딩 벡터 간의 거리가 가까워지는 단점이 있다. 따라서 나는 Bert모델을 이용하여 임베딩 벡터 값을 구해 반의어를 구분할 수 있게 하였고, 이 중에서도 KoSBert모델을 이용하여 한국어에서 임베딩 벡터 값이 더 정확히 나오도록 하였다.
Cosine Similarity
그렇다면 앞에서 설명한 방법으로, 사용자가 작성한 일기의 임베딩 벡터와 다른 일기의 임베딩 벡터 사이의 거리를 구하면, 두 글의 유사도를 측정할 수 있을 것이다.
코사인 유사도(Cosine Similarity)는 두 벡터 간의 유사도를 측정하는 방법 중 하나로, 벡터의 크기가 아닌 방향에 초점을 맞추어 계산하는 방법이다. 이 역시 벡터 간 유사도를 비교할 때 널리 사용되는 기법이며, 이 전 프로젝트 중에서 사용해 본 경험이 있어서 코사인 유사도로 유사도를 측정하였다.
KNN (K-Nearest Neighbors)
그렇다면 앞서 설명한 방법으로, 사용자가 작성한 일기를 벡터로 변환하고 코사인 유사도를 이용해서 유사도를 구하면 되겠다는 생각이 든다.
이 방법을 KNN 알고리즘이라고 하는데, KNN 알고리즘은 주어진 벡터에서 가장 가까운 벡터 K개의 이웃을 찾는 알고리즘이다. 하지만 이 알고리즘의 경우, 모든 일기 벡터에 대해 거리를 계산하는 연산이 수행되기 때문에 비교할 일기의 수가 100만 개라면, 100만 번의 연산이 필요하게 된다.
직관적이기 때문에 매우 정확하다는 특징이 있지만, 데이터가 많아질수록 응답 시간이 느려진다는 단점이 너무 치명적이었다.
ANN (Approximate Nearest Neighbors)
따라서 이런 응답시간이 느린 것을 개선하기 위해서 최근접 이웃 탐색 ANN 알고리즘을 사용하려 한다.
ANN 알고리즘은 대규모 데이터셋에서 KNN 알고리즘의 계산 부담을 줄이기 위해 개발된 방법으로, 완벽한 정확도를 포기하고 근사치를 찾아냄으로써 훨씬 빠르게 결과를 도출하는 방법이다.
ANN 알고리즘의 정확도는 ANN에서 사용하는 알고리즘의 종류의 따라, 또한, 파라미터를 어떻게 설정하는지에 따라 달라질 수 있다. 대표적으로는 ANNOY 알고리즘과 HNSW 알고리즘이 있으며, 두 방식을 비교해 보기로 하였다.
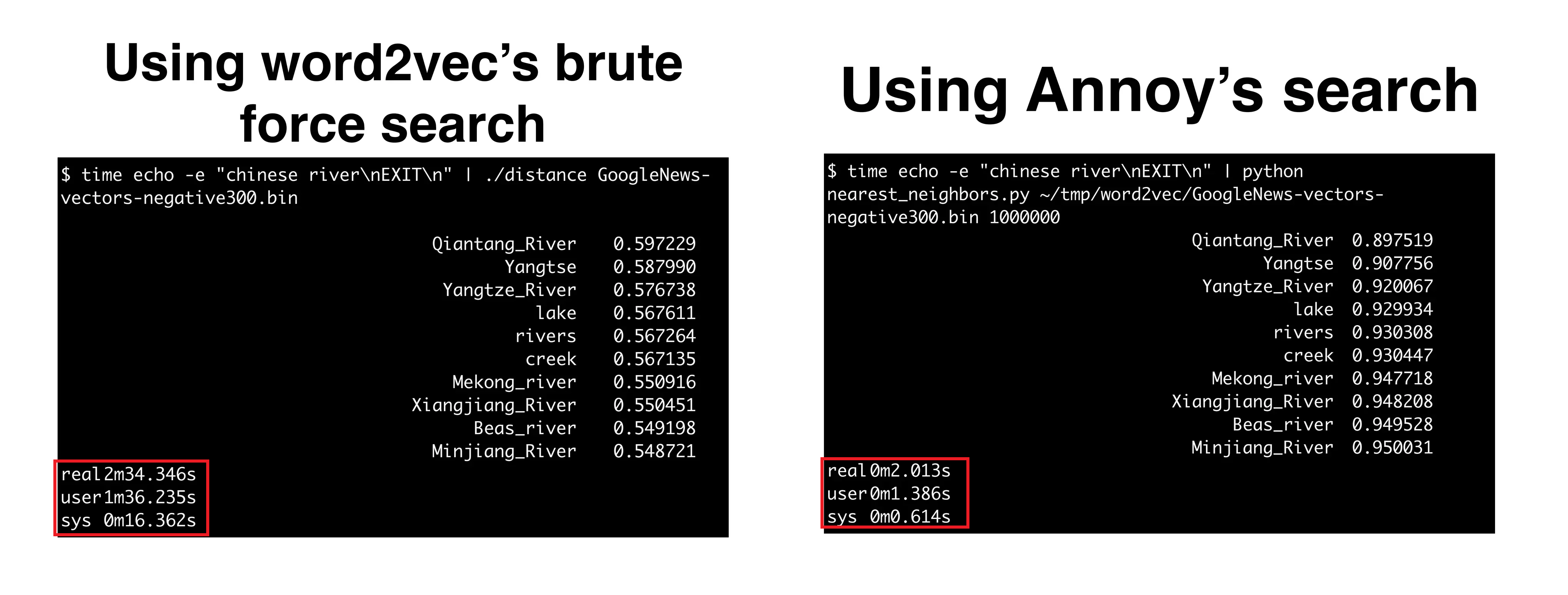
ANNOY (Approximate Nearest Neighbors Oh-Yeah)
ANNOY 알고리즘은 ANN을 대표하는 알고리즘 중 하나로, Spotify에서 개발한 알고리즘이다. 이 역시 ANN 알고리즘의 특징인 완전한 정확도를 포기하고, 매우 빠른 성능을 제공하는 알고리즘으로 추천 시스템에서 많이 활용된다.
특히 고차원 공간에서 최근접 이웃 검색을 위해 설계되었으며, 트리 구조를 사용해서 빠른 속도를 제공한다. 정확도를 높이기 위해서 여러 개의 트리를 구성하는 방법을 사용하며, 이 과정을 병렬처리 함으로 성능을 챙겼다.
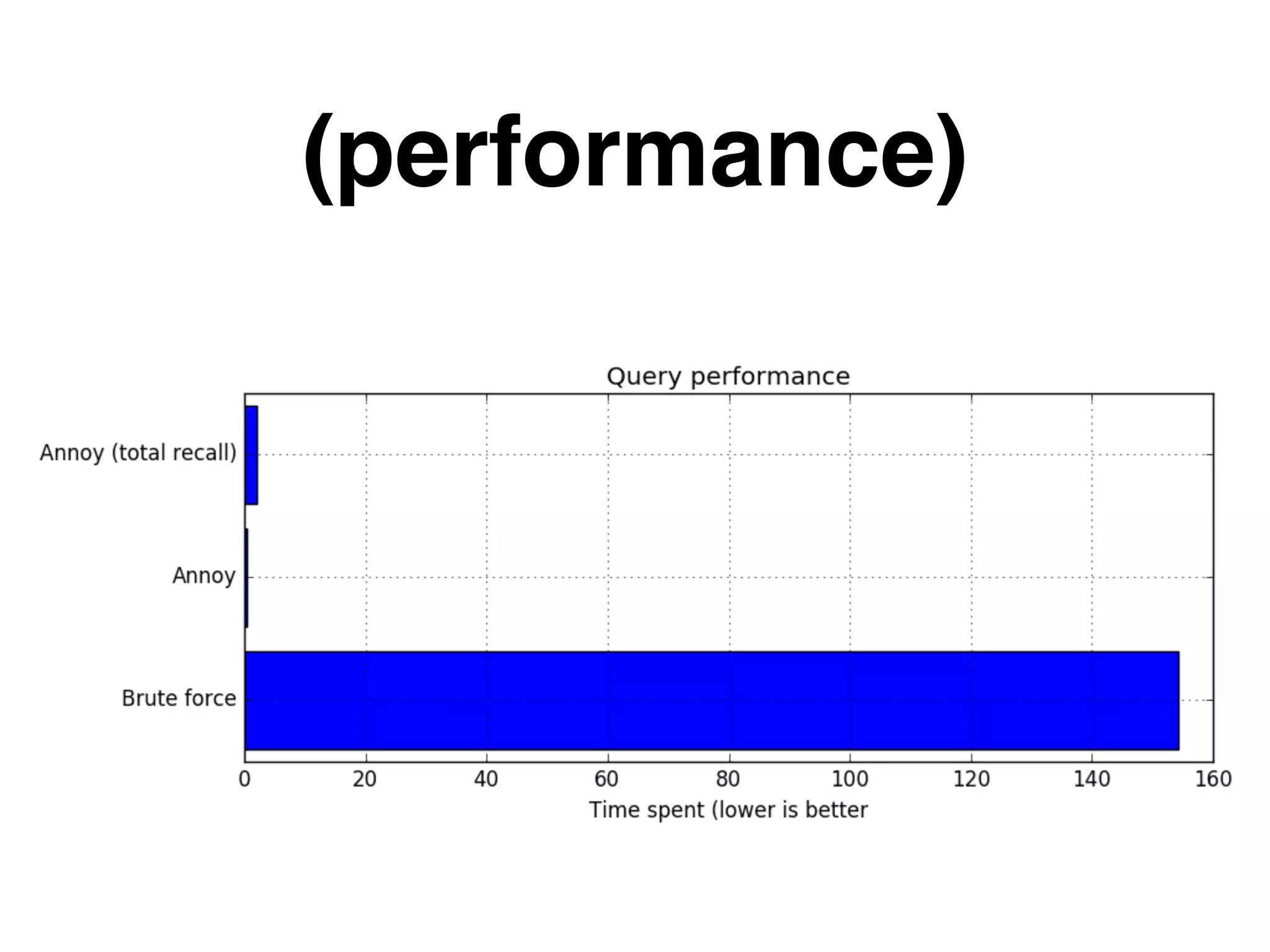
ANNOY 알고리즘 작동 방식
ANNOY의 작동 방식을 내 프로젝트의 상황에 적용해서 설명하려고 한다.
요구사항을 다시 한번 가정하자면, 사용자 일기 데이터가 주어지면 이와 비슷한 다른 일기들을 100개 찾아내야 한다.
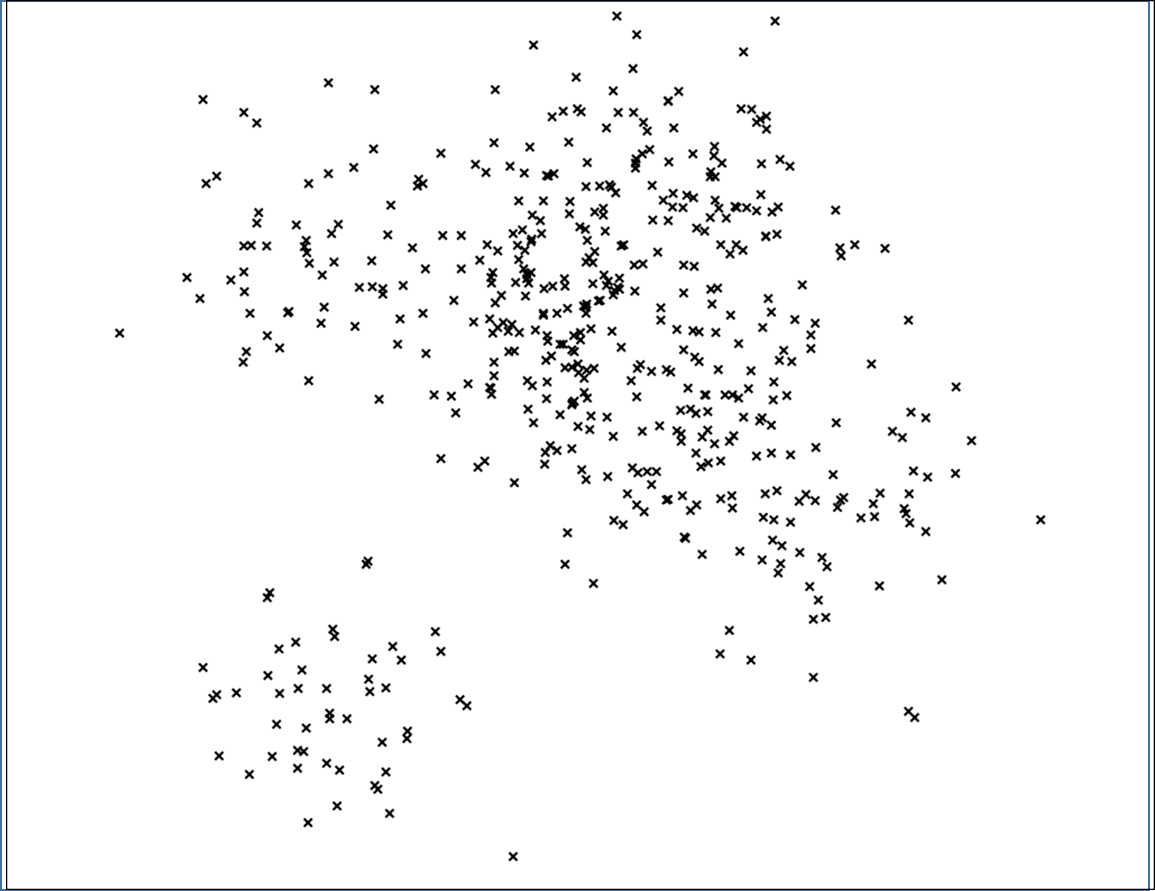
이때, 모든 일기 데이터의 임베딩 벡터들 사이의 거리는 한 평면 위에 위 그림과 같이 표현될 수 있다. 이 평면에서의 점들은 각각 일기 데이터를 표현하며, 각각 벡터 사이의 거리는 유사도를 의미한다고 볼 수 있다.

이제 이 벡터들 중 임의의 2개의 벡터를 선택하여, 전체 공간을 선택한 두 점 사이의 거리가 정확히 반인 두 초평면(Hyperplane)으로 나눈다. 그림을 자세히 보면, 회색 선으로 연결된 두 점이 선택되었고, 이를 두 공간으로 분리한 것을 알 수 있다.

그리고 분리된 각각의 공간 안에서, 또 임의의 두 점을 선택하여 공간을 두 초평면으로 나눈다.

이렇게 나누어진 공간을, 또 임의의 두 점을 선택하여 나눈다. 이때, 각 공간 안의 벡터들의 수가 설정한 K값. 여기서는 100개 미만이 될 때까지 이 과정을 반복하게 된다.
그러면 최종적으로는 오른쪽 그림과 같은 공간이 완성되는데, 이때 같은 색으로 칠해진 공간 안의 벡터는 유사한 벡터로 간주한다.
즉, 입력받은 일기 데이터가 빨간 공간 안에 속한다면, 빨간 공간 안에 있는 모든 벡터들을 반환하는 것이다.
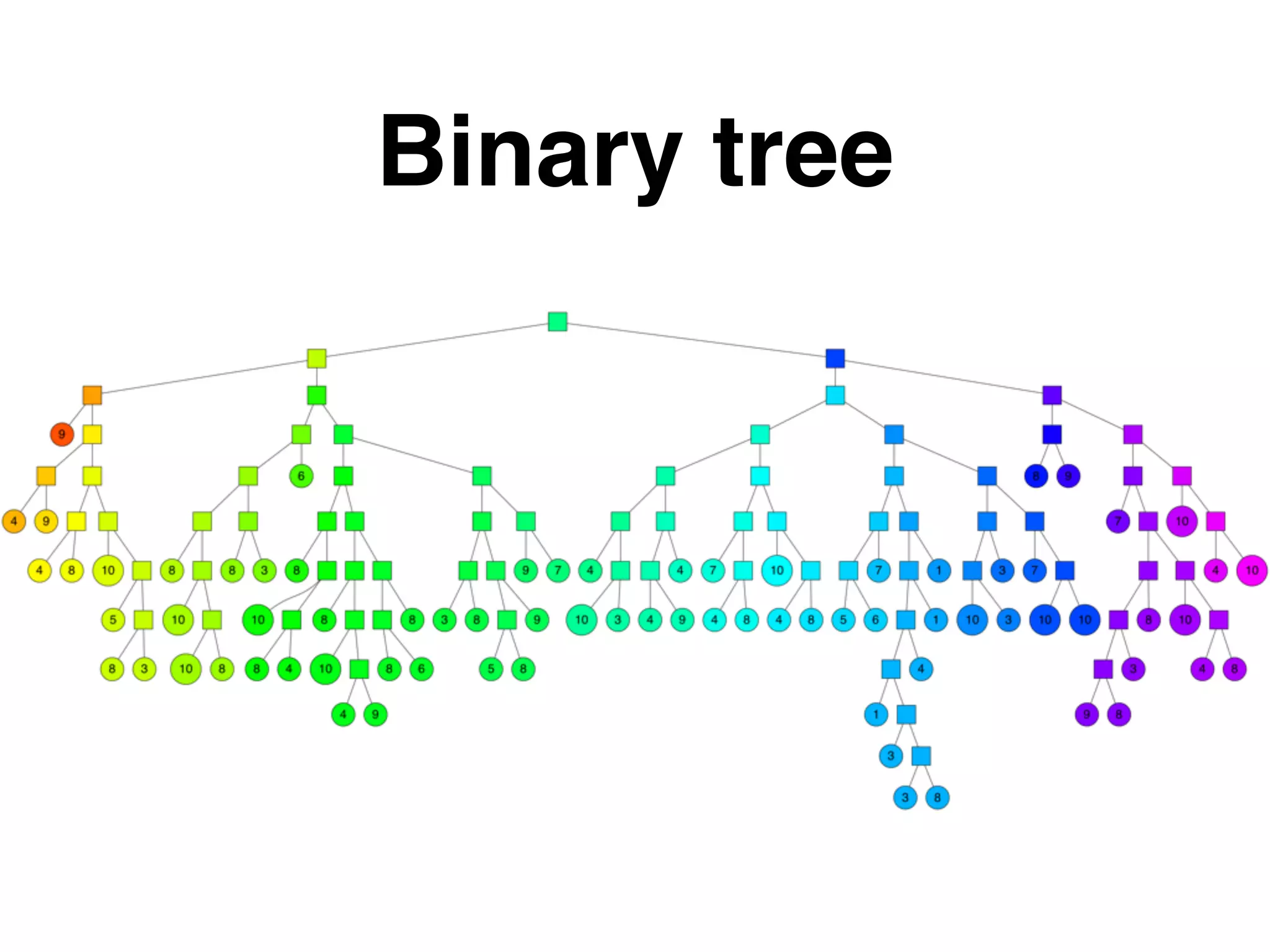
이 과정에서 각 공간을 트리의 노드로 저장하면 위와 같은 그림으로 형성되게 되는 것이고, 각가지의 마지막 노드는 최종 그림에서 한 공간을 의미한다. 즉, 마지막 노드의 수가 K미만인 트리로 형성되는 것이다.
여기까지가 ANNOY에서 알고리즘에 사용할 Tree를 구성하는 방법이다.
그럼 여기서 한 가지 의문이 생긴다. ANNOY에서는 정확도가 아주 조금 떨어진다고 했는데, 앞선 공간 형태의 그림을 보면 벡터 사이의 거리가 너무 멀거나, 한 공간 안에 주어진 K만큼의 데이터가 없을 수도 있지 않나?

ANNOY에서는 이를 해결하기 위해 여러 개의 Tree를 구축하는 방법을 사용한다.
한 Tree를 구축하는 과정은 거의 랜덤적으로 수행되기 때문에 겹치지 않으며, 동일한 방식으로 수행하면 각각 다른 결과가 나오게 된다. 위 사진처럼, 빨간 X표시의 벡터와 유사한 벡터는 각각 색칠된 공간 안에 있다는 뜻이 된다.
최종적으로 여러 개로 구축된 Tree 안에서, 입력된 임베딩 벡터와 같은 공간에 있는 모든 벡터 데이터를 뽑아내서 합치는 작업을 한다. 이때, 중복된 데이터는 제거하게 된다.

그렇다면 결론적으로, 위 그림과 같이 다각형 안에 있는 벡터들을 추천받을 수 있게 된다.
ANNOY 단점
하지만, ANNOY에는 치명적인 단점이 있다.
바로, 구축된 Tree 구조에서 데이터를 추가하거나 삭제하고 싶다면 Tree를 다시 구축해 주어야 한다는 것이다. 이 단점은 정말 치명적인데, 만약 우리 프로젝트에서 사용자가 작성한 일기가 1시간 안에 다른 사용자에게 추천되기를 원한다면, 1시간 안에 Tree를 다시 구축해주어야 했다.
GitHub - spotify/annoy: Approximate Nearest Neighbors in C++/Python optimized for memory usage and loading/saving to disk
Approximate Nearest Neighbors in C++/Python optimized for memory usage and loading/saving to disk - spotify/annoy
github.com
Approximate nearest neighbor methods and vector models – NYC ML meetup
Approximate nearest neighbor methods and vector models – NYC ML meetup - Download as a PDF or view online for free
www.slideshare.net
HNSW(Hierarchical Navigable Small World)
앞선 ANNOY는 데이터를 추가하거나 삭제하기에 너무 불리하기 때문에 HNSW 알고리즘을 추가적으로 조사해 보았다. HNSW 알고리즘은 근사 최근접 이웃 탐색에 사용되는 그래프 기반 알고리즘으로, 이 역시 고차원 데이터에서 뛰어난 성능을 보인다.
케빈 베이컨의 6단계 법칙
HNSW 알고리즘은 재밌는 게, '케빈 베이컨의 6단계 법칙'을 기반으로 만들어진 알고리즘이다.
케빈 베이컨의 6단계 법칙이란, 간단히 말해 세상 모든 사람들을 건너 건너 6단계만 건넌다면 모두 아는 사람들이라는 간단한 이론이다. 예를 들어, 나무위키에서는 케빈 베이컨의 6단계 법칙을 아래와 같이 예를 들고 있다.
-
평범한 정치외교학과 대학생
-
학회에서 만난 서울대 정치외교학과 친구
-
서울대 학생의 지도교수인 서울대 정치외교학과 교수
-
서울대 정치외교학과 교수와 친한 대한민국 외교부 장관
-
대한민국 외교부 장관과 친분이 있는 미국 대통령
문제는 이렇게 가장 빠르게 도달하는 거리를 알아내는 것이 어려울 뿐, 사실은 5단계만 거쳐도 평범한 대학생이 미국 대통령과 아는 사람이 되어 버린다.
Small world network
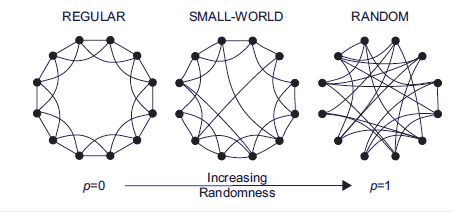
Small world network는 전체 네트워크가 거대하더라도 전체가 서로 가깝게 연결될 수 있다는 이론이다. 예를 들어 맨 왼쪽 그림과 같이 근접한 이웃끼리 연결된 네트워크가 있다고 하자. 이 경우에 몇 개의 선만 랜덤 하게 연결을 해 주면, 평균적으로 다른 네트워크로 이동하는 경로가 줄어들게 되는 것이다.
그렇다면 이 이론을 어떻게 사용할 수 있을까?
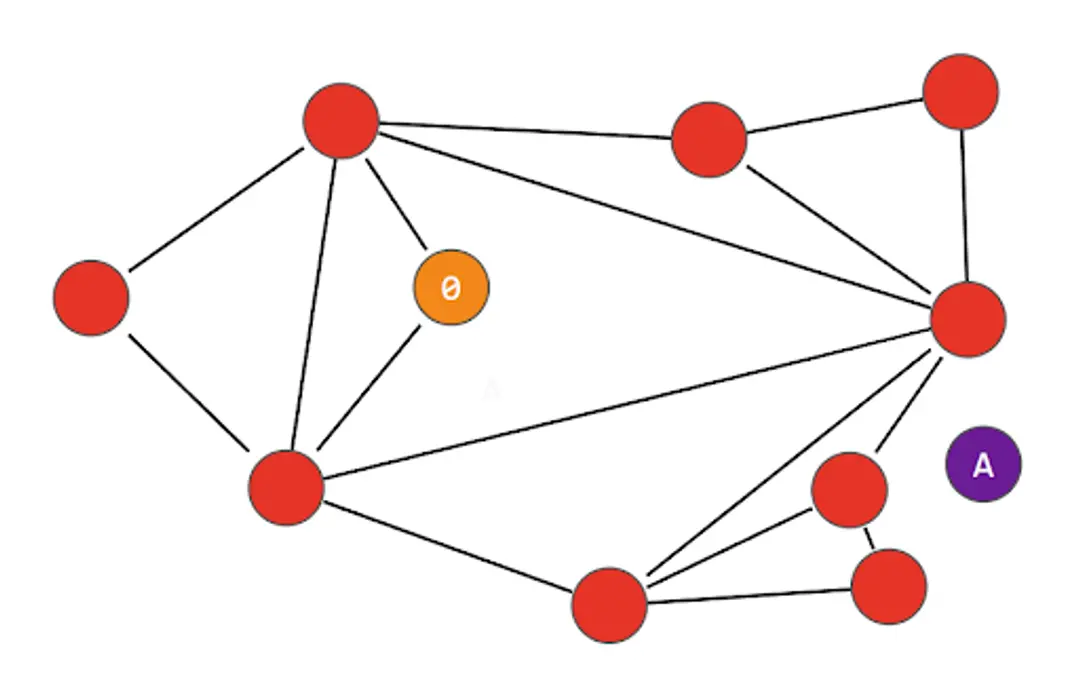
모든 노드들은 삼각형을 기본 형태로 가까운 벡터들끼리 연결되게 구성을 해 놓는다.
그렇다면 위 그림에서 0 노드에서 A 노드로 가기까지, 상당히 많은 노드들을 거쳐서 돌아가야 하는 것을 볼 수 있다. 하지만 여기서 Small world network의 방식대로 랜덤 한 선을 그어준다면 어떻게 될까?
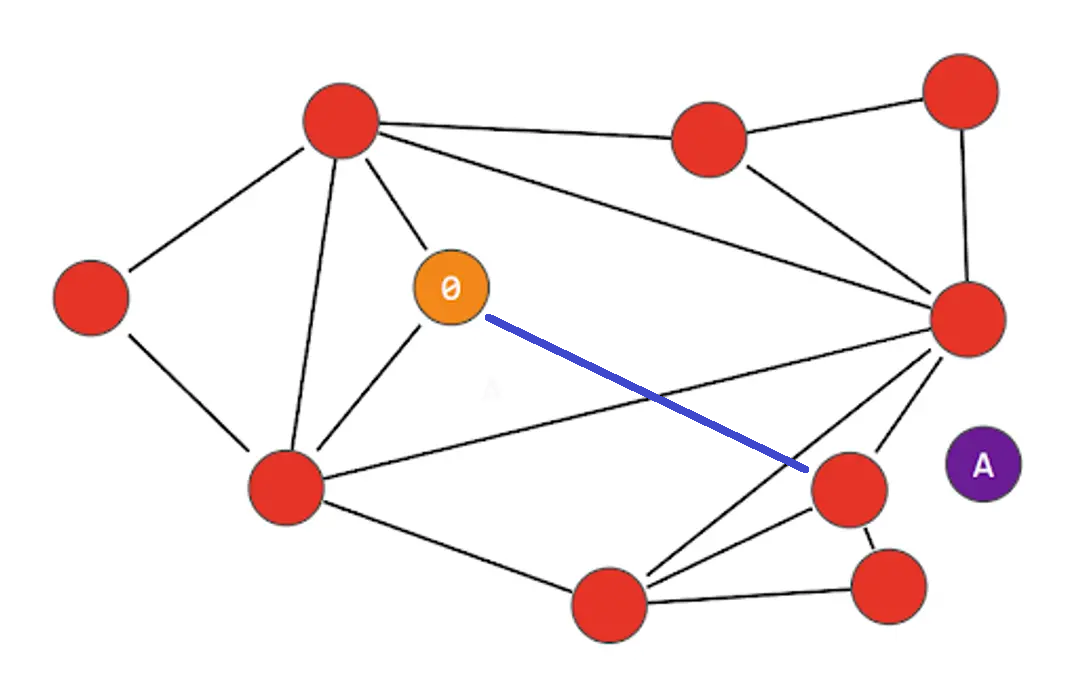
위 그림에서는 보기 편하게 하나의 선 만 파란색으로 표기했다. 그리고 선 하나만 그어주었을 뿐인데, 이웃한 노드만 연결했을 때보다 상당히 가까워진 것을 알 수 있다.
HNSW에서는 이렇게 랜덤 하게 연결하는 방식을 Layer를 통해 구성한다.
HNSW 계층

HNSW 알고리즘은 위 사진처럼 여러 계층(layer)의 그래프로 구성된다. 맨 아래의 계층에는 모든 벡터 데이터들이 표시되고, 한 단계 위의 계층에는 모든 데이터가 확률적으로 올라가게 된다. 예를 들어 확률 p가 1/2라면, 모든 데이터들의 1/2 정도가 상위 계층에 표기되는 것이다.
이때, 상위 계층에 살아남은 노드들을 연결하고, 이 과정을 Small world network에서 랜덤 한 연결을 하는 과정이라고 이해하면 된다.
HNSW 알고리즘은 이런 계층 구조를 이용하여, 단 몇 번 만에 유사한 벡터들을 빠르고 정확하게 도출할 수 있게 한다. 또한 ANNOY 알고리즘과 다르게, 한 번 구성된 계층 안에서 데이터의 추가와 삭제가 발생해도, 동적 업데이트를 지원하도록 설계되었기 때문에 기존 검색 성능에 미치는 영향을 최소화하면서도 계층적 구조를 효과적으로 유지할 수 있다.
HNSW 단점
HNSW를 살펴보다 보면 성능적으로도 우수하고, 데이터의 추가 삭제도 쉽다는 것이 상당히 매력적으로 느껴진다. 하지만 HNSW에도 치명적인 단점이 있는데, 바로 파라미터 튜닝이다.
HNSW에는 파라미터 튜닝이 필수적으로 필요하고, 이 파라미터 튜닝 정도에 따라, 성능과 정확성 면에서 많이 차이가 나게 된다. 설정해야 하는 파라미터 값들은 아래와 같으며, 모든 값들은 서비스에 따라 다르기 때문에 직접 시도를 해 보면서 조정하는 것이 가장 좋다고 한다.
- maxLayer (최대 계층 수): HNSW 그래프의 계층 수. 계층 수가 많으면 더 많은 수준의 추상화를 제공하며, 검색 속도를 향상할 수 있지만, 인덱스 구축 시간과 메모리 사용량이 증가할 수 있다.
- M (각 노드의 이웃 수): 이 파라미터는 각 노드가 유지할 이웃의 수. M이 크면 더 많은 이웃 정보를 유지하여 검색 정확도가 높아질 수 있으나, 메모리 사용량과 인덱스 구축 시간이 증가한다.
- efConstruction (구축 중 탐색 크기): 이 값은 인덱싱 동안 탐색할 노드의 수. 더 큰 값은 인덱스 구축 시 더 나은 품질을 제공하지만, 구축 시간이 길어질 수 있다.
- efSearch (검색 중 탐색 크기): 검색 시 탐색할 노드의 수. 이 값이 크면 검색 정확도가 높아지지만, 검색 시간이 늘어날 수 있다.
결론
내가 진행하는 프로젝트 기능의 요구사항은 데이터 추가와 삭제가 쉽게 일어나는 구조로 되어 있다. 따라서 HNSW로 진행하는 것이 정확도와 기술적인 측면에서 적합하다고 생각된다. 하지만, 프로젝트 자체가 짧은 6주라는 시간 안에 많은 것을 구현해야 하고, 이미 기획과 설계에서 많은 시간을 쓴 상태였다. 따라서 파라미터 튜닝을 할 시간을 확보하지 못했고, 파라미터 튜닝에 따라 성능과 정확성 차이가 많이 나는 HNSW 대신, 바로 사용이 가능한 ANNOY를 사용하기로 했다.
ANNOY를 사용했을 때의 가장 큰 문제는, 새로운 데이터가 추가, 삭제됨에 따라 새롭게 Tree를 구성해야 한다는 것이다. 만약 이 과정에서 데이터가 많아진다면 Build 시간 자체가 오래 걸리게 되어, 새로운 데이터 추천이 이루어지기까지의 시간이 오래 걸리게 될 것이다.
이 문제에 대해 여러 가지 레퍼런스를 찾아본 결과, NHN Cloud의 NHN FORWARD22에서 ANNOY 알고리즘을 사용한 경험을 발표한 자료를 찾을 수 있었다. 이 발표에서 NHN Cloud는 ANNOY 알고리즘을 사용하여 추천시스템을 만들었고, 2시간마다 Tree를 새롭게 Build 하는 작업을 통해 새로운 데이터를 추가하였다고 한다. 또한, 200만 건에서 250만 건 이상의 데이터를 처리할 때 1시간 정도의 빌드시간이 걸렸고, 이 빌드시간에 대한 이슈를 해결하기 위해 HNSW를 도입하게 되었다고 설명한다.
이 사례를 예시로, 초기 서비스인 우리 프로젝트에서는 빌드에 시간이 오래 걸리지 않을 것으로 판단했다. 따라서, 우리 프로젝트에서 2시간 간격으로 새롭게 Tree를 구성해 주는 스케줄러를 구성함으로써, 데이터의 추가와 삭제에서의 문제를 해결했다. 또한, 우리 프로젝트도 앞선 사례를 바탕으로 서비스가 운영됨에 따라 데이터가 많이 쌓여서 Tree를 구성하는 시간이 오래 걸리게 되는 불편함을 겪게 된다면, HNSW 알고리즘을 도입하여 시스템 성능을 개선하기로 결정하였다.
'Spring > Project' 카테고리의 다른 글
| [Java] IntelliJ Profiler로 병목지점 찾아, Java ImageIO 성능 개선하기 (5) | 2024.10.03 |
|---|---|
| [디자인 패턴] 전략 패턴(Strategy Pattern), 팩토리 패턴(Factory Pattern), 레지스트리 패턴(Registry Pattern) (1) | 2024.07.30 |
| [토이 프로젝트] 블로그를 깃허브에 효과적으로 노출시키는 방법 (2) | 2024.03.28 |
| [Pose Estimation] Mediapipe 2배속 분석과 분석 결과 중간 부족한 프레임 채우기 (1) | 2023.04.21 |
| [Pose Estimation] Mediapipe Pose 3D grid에 새로운 축을 적용하고, 새로운 축으로 좌표 변환하기 (4) | 2023.04.04 |



