olrlobt
[Pose Estimation] YOLOv5, MediaPipe로 Multi Pose 구현 시도해보기 본문
Media pipe
Media pipe는 Google에서 제작한 Machine Lunning Solution으로 얼굴추적, 손추적, 객체 인식과 같은 다양한 기능들을 제공한다.
또한, 사람의 자세 인식 Pose 추적이 가능하지만 오직 한 사람의 Pose를 추정하는 기능을 제공한다.
한 사람의 Pose를 추적하는 코드를 구현하기를 원한다면, 이 전 게시글인 아래의 포스팅을 확인하길 바란다.
https://olrlobt.tistory.com/50
[Pose Estimation] MediaPipe Pose / 미디어 파이프로 사람 자세 인식 JavaScript 구현하기
Media pipe Media pipe는 Google에서 제작한 Machine Lunning Solution으로 얼굴추적, 손추적, 객체 인식과 같은 다양한 기능들을 제공한다. Media pipe에서 제공하는 기능들은 아래에서 확인 가능하며, 자세히는
olrlobt.tistory.com
MediaPipe Multi Pose
앞선 설명처럼, Media pipe는 오직 한 사람의 Pose 추적만 가능하다. Open Pose와 Pose Net의 경우, 멀티 포즈를 기본적으로 제공하는 것으로 알고 있다. 그럼에도 Media pipe로 시도하려는 이유는 3D 좌표 지원과 비교적 많은 자료의 양. 그리고 Media pipe 자체가 Pose Net의 상위 버전으로 알고 있는데, Pose Net만 멀티포즈를 지원한다니 왜 안 되는지 의문을 갖게 되었다.
또한 해외 포스팅들을 찾아보면, Media pipe로 Multi Pose를 구현했다는 글들이 가끔 보이기도 한다.
그래서 도전해 보고 싶어졌다.
아이디어
기본적인 아이디어는 Media pipe에서 아주 우수한 성능으로 잘 작동하는 Single Pose를, 각 사람 별로 수행하기만 하면 Multi Pose가 되는 것이지 않나? 에서 시작되었다.
ML Solution 중, 객체 탐지기를 이용하여 각 사람 별로 BoundingBox를 만들고, 이를 Pose를 통하여 전송 비교하면 될 것이라 생각했다.
Pose 기능이 MediaPipe를 이용하기 때문에, MediaPipe에서 제공하는 객체 탐지기인 Objectron을 사용하면, 쉽게 연동되어 구현이 될 것이라 생각했지만, Objectron의 경우 학습된 물체의 가짓수가 제한되어 있고, 사람은 학습이 되어있지 않아, 사용자가 직접 학습시켜야 했다.
따라서 나는 Objectron이 아닌 Tensor Flow의 객체 탐지를 이용하기로 하였다.
COCO-SSD 사용하기
COCO-SSD는 객체 감지 (Object Detection) 알고리즘 중 하나로, Tensor Flow.js 라이브러리를 사용하여 웹 브라우저에서 객체 감지를 수행할 수 있다.
Tensor Flow는 Google에서 개발한 오픈소스 ML 학습 라이브러리로 다양한 러닝 모델을 구축하고 학습하는 데 사용된다.
Tensor Flow의 객체 탐색이 여러 명이 되는지 이미지로 간단히 테스트해 보았다.
이미지 :

간단하게 바운딩 박스(bbox)가 나오는 것을 확인했으며, 가장 좌측 사람의 경우 score가 낮아 감지되지 않은 모습이다.
잘 되고, 결과 값의 bbox 역시 잘 출력되는 것을 확인해서, 바로 비디오로 넘어갔다.
비디오 :
영상 역시 문제없이 객체가 잘 탐지되기는 하지만, 문제점이 발견되었다.
내가 수행하려는 기능은 bbox 자체가 아닌, bbox 별로 사람의 포즈를 탐색하는 것이기 때문에 높은 정확도와 빠른 속도를 요구하는 bbox 탐지 기술이 필요하다.
하지만 Tensor Flow의 경우, 눈으로 보아도 초당 2회 정도 측정 되는 것으로 보이고, 팔이 bbox를 빠져나오는 경우가 허다하게 발생하였다.
이렇게 되면, bbox별로 객체를 분리해 내더라도 신체의 일부가 잘리게 됨으로 pose 측정에서 정확한 값을 얻을 수 없다.
YOLOv5 사용하기
YOLOv5는 객체 감지 (Object Detection) 알고리즘 중 하나로, YOLO (You Only Look Once) 알고리즘의 다섯 번째 버전이다. 현재는 YOLOv7까지 나온 것으로 알고 있지만, 7 버전을 사용하기 위해선 모델을 JS로 변환하고 학습시키는 과정을 따로 진행해야 하기 때문에, JS버전이 오픈되어 있는 v5를 사용하였다.
비디오 :
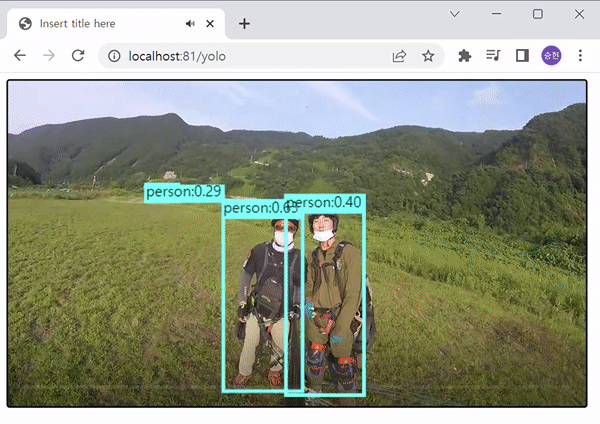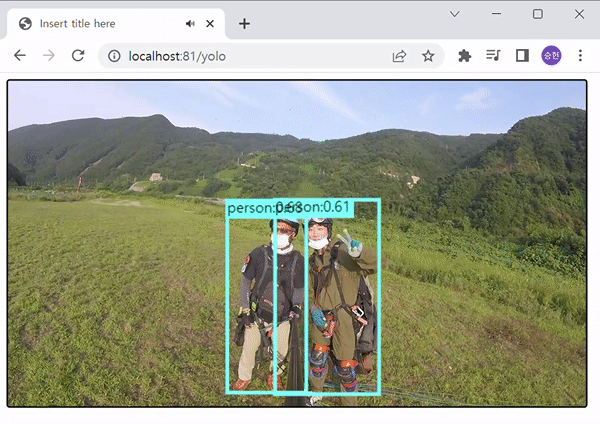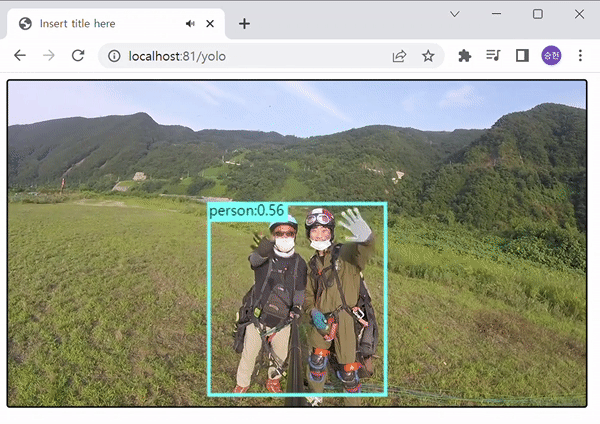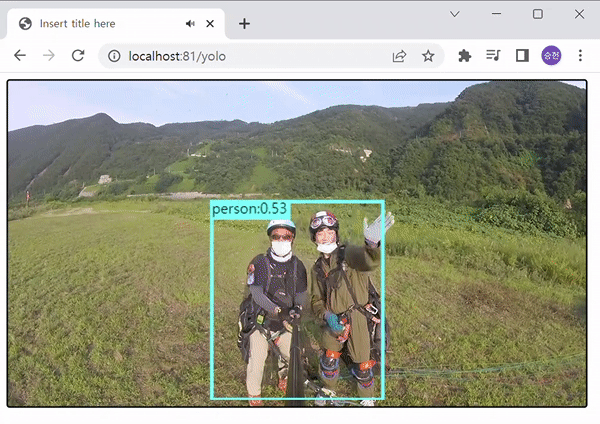
YOLOv5를 사용하여 객체 탐지를 진행하였다. 보이는 것과 같이 COCO-SSD 보다 속도와 정확성 면에서 월등히 우수한 면을 보여준다. 이 정도 속도로 탐지만 가능하더라도, Pose 측정에는 무리가 없을 것으로 판단하여, YOLOv5로 멀티포즈를 시도해 보기로 하였다.
멀티포즈 구현
이미지 :
비디오로 멀티포즈를 구현하기에 앞서, 내가 생각한 방법이 안 될 수도 있다고 생각했기 때문에, 이미지로 먼저 실험을 진행해 보았다.
실험 순서는 다음과 같이 진행했다.
1. 먼저 YOLOv5에서 구분된 객체에서 Person만을 찾아낸다.
2. 이 Person 객체를 BBox 별로 나누어 Canvas에 이미지화시킨다.
3. 이미지화시킨 Canvas를 Pose 분석을 실행한다.

일단 위의 그림에서 맨 왼쪽만 DOG로 인식이 되었고 나머지는 Person으로 잘 인식되었다.
이를 BBox가 그려지는 함수에서 person만 찾을 수 있게 조건 식을 걸고, Tensor 객체로 주어진 BBox 좌표를 이용하여 이미지를 등분해 주었다.

위와 같이 이미지가 잘 나오는 것을 확인했고, 이를 Media Pipe의 Pose를 이용하여 포즈 분석을 실시하였다.
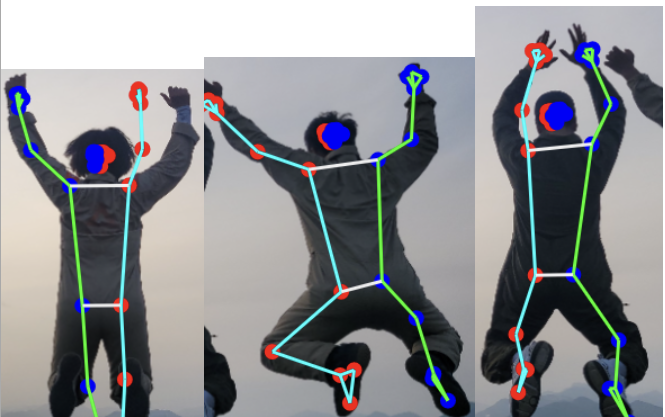
사람으로 추정하기 힘들기 때문에 오차가 나는 것 빼고는, 인식을 굉장히 잘하는 모습을 알 수 있었다.
동영상:
이제, 이미지에서 실행한 방법을 동영상에서 그대로 실행에 옮겼다.
Person을 구분해 내서 bbox로 출력하는 작업을 했다.

그 결과, 사람을 분석해서 잘라내는 데까지는 성공했지만,
tensor flow가 yolo를 이용하여 객체를 선정할 때, 순서를 지정해 주지 못하였다. ( 아마 랜덤인 듯하다. )
먼저 탐지되는 순서대로 뿌려주는 문제가 있었고,
아무래도 탐지된 객체를 잘라내어 이미지로 만들고 그려주는 작업을 진행하다 보니 속도가 더딘 것을 느낄 수 있었다.
여기서 Pose 분석까지 진행하게 되면 더 느려지게 될 테니만, 확인 차 구현을 진행하였다.
그 결과
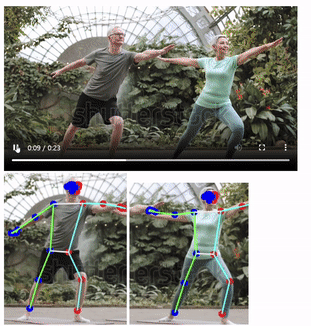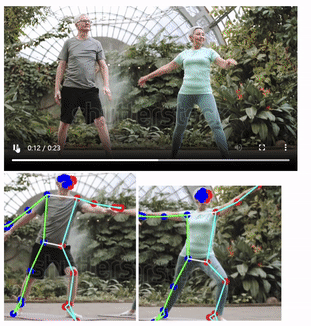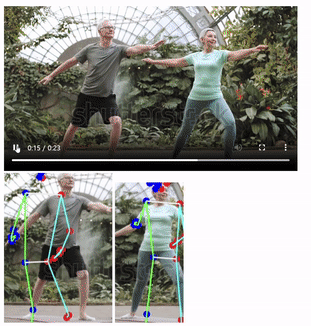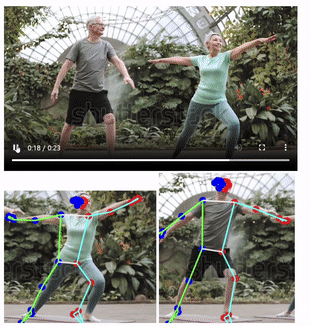
속도가 많이 더뎌질 것으로 예상했지만, 속도는 비슷하게 느껴졌다.
이 말은 즉, 객체를 탐지하여 bbox를 만드는 작업의 속도를 높인다면, 실시간성이 올라간다는 이야기다.
하지만, 속도를 높이려면 다른 탐지기를 써야 하는데 JS에서의 구현이 쉽지 않다.
또한, 영상에서 확인할 수 있듯이, 사람이 겹치게 되거나, 객체탐지 단계에서 사람의 일부분이 잘린다면, Pose 분석이 제대로 이루어지지 않는다.
결론
이로서, Multipose를 지원하는 모델을 사용하거나, 학습을 시키는 방법이 아닌 이상, Multipose를 구현하기 어렵다는 것을 알게 되었다. 토이프로젝트에 Multipose 기능을 활용하고 싶은데, 다른 방안을 찾아봐야겠다.
'Spring > Project' 카테고리의 다른 글
| [Pose Estimation] Mediapipe Pose 분석 결과 3D grid로 렌더링하기 (0) | 2023.04.03 |
|---|---|
| [Spring boot] FFmpeg로 영상 배속 설정하기 (0) | 2023.03.31 |
| [Pose Estimation] MediaPipe Pose / 미디어 파이프로 사람 포즈 감지하기 (0) | 2023.03.15 |
| [Pose Estimation] 다양한 Pose Estimation API 비교와 정리 (5) | 2023.03.14 |
| [Spring boot] 카카오 포즈 / RestTemplate으로 Kakao Pose API 호출하기 (0) | 2023.02.28 |



